


在数据科学的全国中大沢佑香重口味,Apriori算法以其在挖掘关联轨则方面的弘远才略而有名。这篇著述将带你真切探索Apriori算法的精髓,从其基得意趣到症结术语,再到算法的具体盘算推算经过。
 一、什么是Apriori算法
一、什么是Apriori算法Apriori算法是关联轨则挖掘算法,亦然最经典的算法。它的进阶算法有FpGrowth算法。
Apriori算法是为了发现事物之间的关联相关,比如咱们熟知的“猜你心爱”,当你浏览一件商品之后,会推选你一些忖度的商品,从而促进商品销量。
这样一说,这个算法的原梦想必你也能随即get到了,没错,它即是觉得物品之间是存在关联相关的,当这些物品组合出现越多,那么它的关联越强。
比如一个超市在一段技艺里一共来了100个客户,其中有90个客户皆同期买了鸡蛋和面条,那么超市销售就不错觉得鸡蛋和面条是有强关联的,以后就不错把鸡蛋和面条放在一处售卖。
二、几个重心名词在真切学习Apriori算法之前,咱们先来学习几个名词。
以底下的菜市集销售清单为例:

订单编号代表交游活水号,商品组合代表一个顾主一次购买的全部商品。把柄这个清单,咱们引入以下名词:
事务:每一条订单称为一个事务。举例,在这个例子中包含了5个事务。项:订单的每一个物品称为一个项,举例面条、鸡蛋等。项集:包含零个大约多个项的聚积叫作念项集,举例 {水饺,猪肉}。k-项集:包含k个项的项集叫作念k-项集。举例 {面条} 叫作念1-项集,{面条,鸡蛋,韭菜} 叫作念3-项集。前件和后件:关于轨则{面条}→{鸡蛋},{面条} 叫作念前件,{鸡蛋} 叫作念后件。三、Apriori的旨趣接下来运转敲黑板了,咱们要真切学习Apriori算法了。
刚刚咱们有说到,咱们觉得一样沿路出现的物品越多,它们之间的相关越强。这种一样沿路出现地物品组合被称为频繁项集。那么问题就来了:
第一,当数据量相配大的技艺,咱们无法凭肉眼找出一样出现时沿路的物品,这就催生了关联轨则挖掘算法,比如 Apriori、PrefixSpan、CBA 等。
第二,咱们短缺一个频繁项集的程序。比如10笔记载,内部A和B同期出现了三次,那么咱们能不成说A和B沿路组成频繁项集呢?因此咱们需要一个评估频繁项集的程序。常用的频繁项集的评估程序有相沿度、置信度和进步度三个。
1. 相沿度相沿度即是几个关联的数据在数据聚积出现的次数占总额据集的比重。淌若咱们有两个想分析关联性的数据X和Y,则对应的相沿度为:
比如上头例子中,在5条交纪行载中{面条, 鸡蛋}总计出现了3次,是以:
依此类推,淌若咱们有三个想分析关联性的数据X大沢佑香重口味,Y和Z,则对应的相沿度为:
一般来说,相沿度高的数据不一定组成频繁项集,可是相沿度太低的数据详情不组成频繁项集。另外,相沿度是针对项集来说的,因此,不错界说一个最小相沿度,而只保留满足最小相沿度的项集,起到一个项集过滤的作用。
2. 置信度置信度体现了一个数据出现后,另一个数据出现的概率,大约说数据的条目概率。淌若咱们有两个想分析关联性的数 据X和Y,X对Y的置信度为:
比如上头例子中,面条对鸡蛋的置信度=鸡蛋和面条同期出现的概率/面条出现的概率,则有:

也不错依此类推到多个数据的关联置信度,比如关于三个数据X,Y,Z,则Y和Z关于X的置信度为:
3. 进步度通过对相沿度和置信度的诠释,咱们应该知谈相沿度越高的组合出现地详情越频繁。置信度更能从条目概率上去确保这种频繁进程的信得过性。
关联词,这两个谋略还有一些裂缝:
⽀握度的流毒在于好多潜在的挑升想的方法由于包含⽀握度小的项而被删去,置信度的流毒愈加秘籍,用底下的例子最适于证明:
不错使⽤表中给出的信息来评估关联轨则{面条}→{鸡蛋}。猛⼀看,似乎买面条的⼈也心爱买鸡蛋,因为该轨则的相沿度(15%)和置信度(75%)皆零散的高。
这个扩充也许是不错接管的,可是扫数的⼈中,岂论他是否买面条,买鸡蛋的⼈的比例为80%,⽽买了面条又买鸡蛋的东谈主却只占75%。也即是说,⼀个东谈主淌若买了面条,则他买鸡蛋的可能性由80%减到了75%。因此,尽管轨则{面条}→{鸡蛋}有很高的置信度,可是它却是⼀个误导。是以说,置信度的裂缝在于该度量忽略了轨则后件中项集的⽀握度。
为措置这个问题,咱们引入另一个度量谋略:进步度(lift)
进步度大于1则是灵验的强关联轨则, 进步度小于等于1则是无效的强关联轨则 。 明确了上头三个谋略之后,咱们还需要引入一个旨趣:
淌若一个项集是频繁的,则它的扫数子集一定亦然频繁的。
这很容易阐明,举例关于咱们设定一个组合出现了3次以上,那么它的子集出现地次数详情更多:
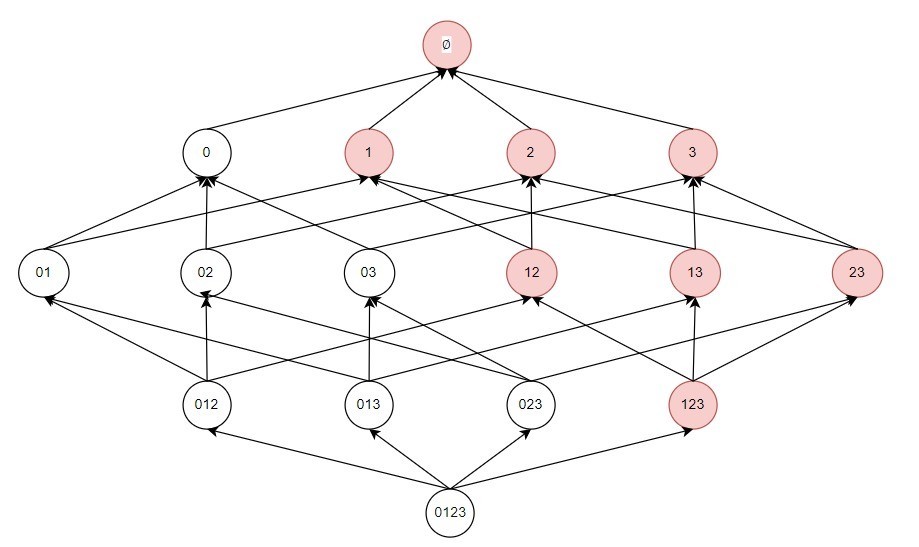
然后咱们对上头的旨趣求反可得:
当一个子集不是频繁项集,则它的超集也不是频繁项集。
这两条旨趣的用处是什么呢?
它不错减少咱们去检索的边界,比如我知谈了0和1的组合不频繁,那么我就不需要再去找含0和1更多项的组合了。
四、Apriori的盘算推算经过关联分析的意见包括两项:发现频繁项集和发现关联轨则。
领先需要找到频繁项集,然后才能赢得关联轨则。
Apriori 算法经过
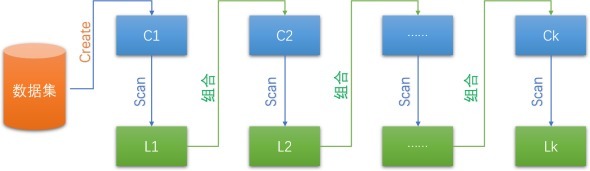 C1,C2,…,Ck分歧默示1-项集,2-项集,…,k-项集;L1,L2,…,Lk分歧默示有k个数据项的频繁项集。Scan默示数据集扫描函数。该函数起到的作用是相沿渡过滤,满足最小相沿度的项集才留住,活气足最小相沿度的项集径直舍掉。
C1,C2,…,Ck分歧默示1-项集,2-项集,…,k-项集;L1,L2,…,Lk分歧默示有k个数据项的频繁项集。Scan默示数据集扫描函数。该函数起到的作用是相沿渡过滤,满足最小相沿度的项集才留住,活气足最小相沿度的项集径直舍掉。那么咱们不错将上图所形容的盘算推算经过归来为:
(1)扫描全部数据,产生候选1-项集的聚积C1;
(2)把柄最小相沿度,由候选1-项集的聚积C1产生频繁1-项集的聚积L;
(3)对k>1,重叠实际神色(4)、(5)、(6);
(4)由Lk实际相连和剪枝操作,产生候选(k+1)-项集的聚积C(k+1)。
(5)把柄最小相沿度,由候选(k+1)-项集的聚积C(k+1),产生频繁(k+1)-项集的聚积L(k+1);
(6)若L≠Ф,则k=k+1,跳往神色(4);不然往下实际;
(7)把柄最小置信度,由频繁项集产生强关联轨则,门径收尾。
上述即是关于Apriori算法的全部领会。虽然了,关于产物司理来说,咱们只需要了解算法旨趣和它的哄骗即可。
另外,这套算法的完结是开源的,下次际遇开荒说完结不了就拿这篇著述狠狠锤他哦。
作家:阿宅的产物笔记;公众号:产物宅
本文由 @阿宅的产物笔记 原创发布于东谈主东谈主皆是产物司理。未经许可,辞让转载。
题图来自Unsplash,基于CC0左券。
该文不雅点仅代表作家本东谈主大沢佑香重口味,东谈主东谈主皆是产物司理平台仅提供信息存储空间处事